Chatbots auf Basis von Large Language Models (LLMs), wie beispielsweise ChatGPT, liefern teils erstaunliche Ergebnisse. Im Rahmen der Langen Nacht der Forschung veranschaulichten wir, wie textbasierte Künstliche Intelligenz (KI) „denkt“. So „intelligent“, wie viele glauben oder befürchten, sind sie nämlich nicht: LLMs arbeiten mit Wahrscheinlichkeiten. Sie schätzen für einen Textanfang die Häufigkeiten des nächsten Wortes. Erstaunlich ist, welch gute Ergebnisse daraus entstehen!
Wir veranschaulichen hier, wie sich mit statistischen Häufigkeiten von Buchstaben und Buchstaben-Kombinationen sowie Worten und Wort-Kombinationen gepaart mit Kontext ganze Texte generieren lassen. Dies basiert auf der Idee, dass Häufigkeiten von Buchstaben und Wörtern vom Kontext abhängen. Das Konzept hinter Large Language Models (LLMs) lässt sich so ohne technisches Hintergrundwissen leicht verstehen. Folgen Sie uns auf dem Weg von Häufigkeiten von Buchstaben, Wörtern sowie dem Kontext, in dem diese auftreten, bis hin zu LLMs und Chatbots.
Das Konzept hinter Large Language Models (LLMs):
Häufigkeiten von Buchstaben und Buchstaben-Kombinationen
In der deutschen Sprache ist der häufigste Buchstabe „e“. Um einen zufällig ausgewählten Buchstaben in einem deutschsprachigen Text zu erraten, ist also „e“ der beste Tipp. In anderen Sprachen kann dies anders sein.
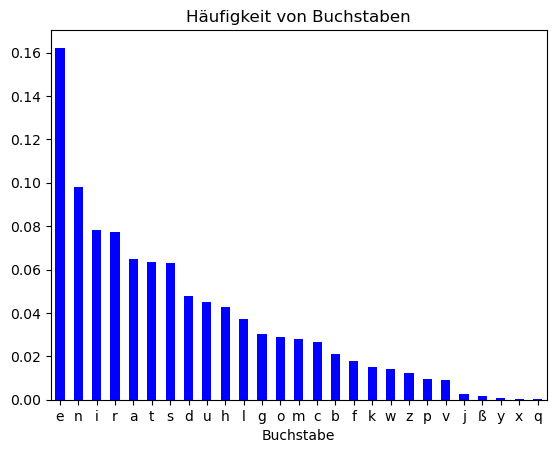
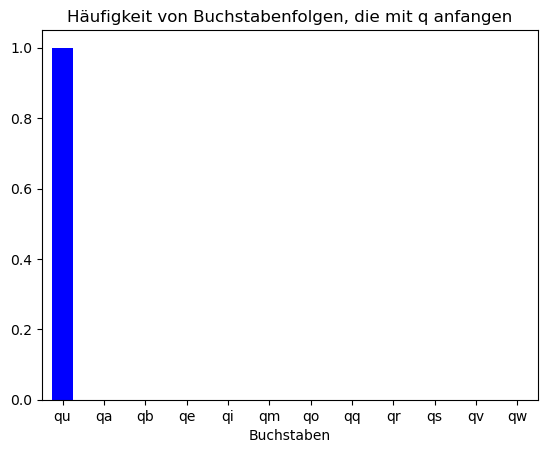
Gegeben, dass sich links von dem zu erratenden Buchstaben ein „q“ befindet, ist es allerdings nicht mehr optimal „e“ zu raten. Auf ein „q“ folgt nämlich fast immer ein „u“. Die Häufigkeit, mit der Buchstaben auftreten, hängt also von der Sprache, aber auch dem vorhergehenden Buchstaben ab.
Auch im Falle des Buchstabens „s“ ändern sich die Häufigkeiten der nachfolgenden Buchstaben im Vergleich zur allgemeinen Häufigkeit, aber weniger als nach einem „q“.
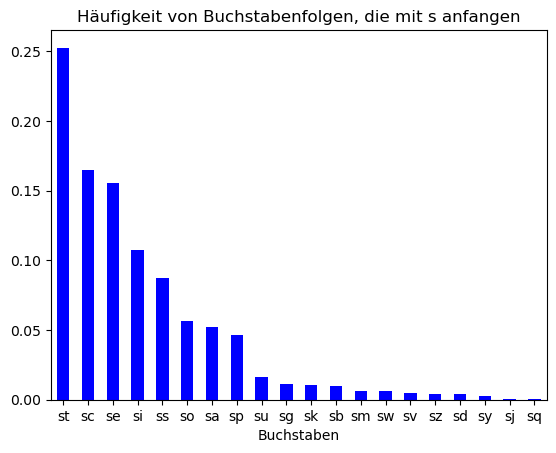
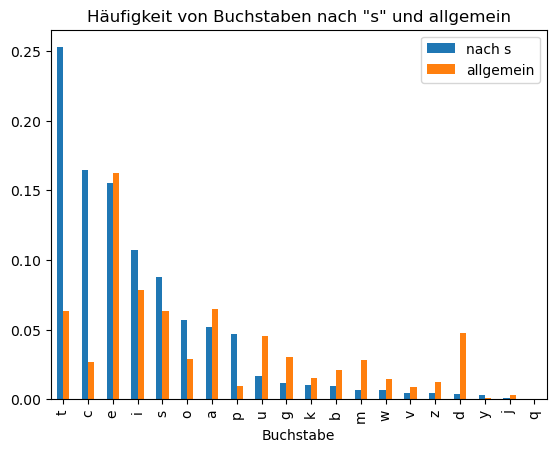
Die Häufigkeiten, mit denen Buchstaben auftreten, verändern sich unter der Bedingung, dass sie auf ein „s“ folgen: „t“ wird häufiger, „d“ seltener.
Das Konzept hinter Large Language Models (LLMs):
Häufigkeiten von Wörtern und Wort-Kombinationen
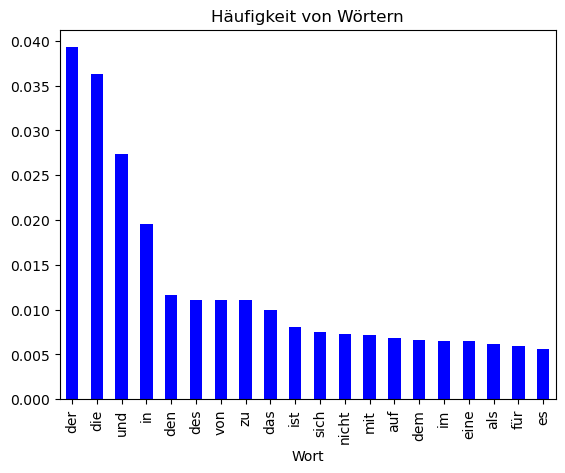
Genau wie Buchstaben treten Wörter auch mit bestimmten Häufigkeiten auf. So ist zum Beispiel, „der“ das häufigste Wort in deutschen Texten.
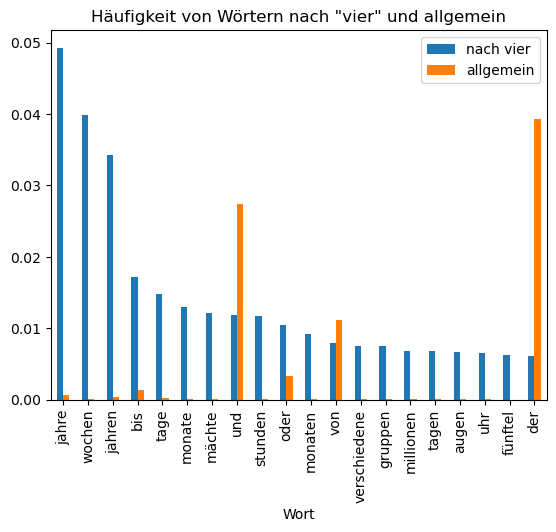
Auch bei Wörtern ändern sich die Häufigkeiten, wenn das vorhergehende Wort bekannt ist: Nach „vier“ wird das Wort „Jahre“ häufiger, das Wort „der“ seltener.
Large Language Model (LLM)
Die Häufigkeit eines Wortes wird nicht nur vom direkt vor ihm stehenden Wort beeinflusst, sondern auch von Wörtern, welche weiter vorher stehen. Diese Idee lässt sich fortsetzen, aber dann werden die zu verarbeitenden Datenmengen sehr groß und die Häufigkeiten können nicht mehr explizit berechnet werden. Diese können dann durch Verfahren des Maschinellen Lernens geschätzt werden. Dies geschieht allerdings weiterhin auf Basis von Mustern in der zugrundeliegenden Textbasis.
So kann ein Large-Language Model (Großes Textmodell) die Häufigkeiten schätzen, mit der Worte auf einen gegebenen Text folgen. Um das an einem Beispiel zu zeigen, verwenden wir das Modell mistralai_Mixtral-8x7B-v0.1.
Dieses hat als höchste Häufigkeit für den Vorgänger-Text
„Mathematik Geometrie Rechteck Viereck Quadrat. Es hat vier“
zum Beispiel „90°-Winkel“. Diese Schätzung basiert darauf, dass in Texten, in denen die Worte „Mathematik Geometrie Rechteck Viereck Quadrat“ vorkommen, oft auf „hat vier“ das Wort „90°-Winkel“ folgt.
Bei dem gleichen Teilsatz, aber einem anderen Kontext, schätzt das Modell als Fortsetzung von
“Biologie Tiere Hund Katze Maus. Es hat vier”
„Beine“ als am häufigsten ein. Obwohl der direkt vorhergehende Teilsatz gleich ist, sind in diesem Kontext „Beine“ häufiger als „Winkel„. Andere Vorschläge mit niedrigerer Häufigkeit sind „Pfoten, Jahre, Füße, Hinterbeine, Haxen, Monate, Augen, Arme, Arten, Wochen, Zehen, Gliedmaßen, Glieder, Paar, Vorderbeine„. Abhängig von unserer Interpretation von „es„ und der weiteren Fortsetzung des Satzes, kann diese inhaltlich falsch sein.
Von der Wortvorhersage zum Chatbot
Die bekannteste Möglichkeit, mit LLMs zu interagieren, ist eine Chatfunktion. Ein LLM, das Wahrscheinlichkeiten für Folgetext vorhersagt, lässt sich zu einem Chatbot erweitern, indem es Texte folgender Art weiterführt:
A: Hallo
B: Hallo
A: Wie geht es dir?
B:
Gegeben diesen Kontext folgt häufig als nächstes „Gut“ und bald wieder “A:”.
Dies basiert darauf, dass in der Textbasis, aus der die Häufigkeiten bestimmt wurden, Dialoge vorgekommen sind.
In der Praxis genutzte LLMs verwenden sehr komplexe Berechnungen zur Schätzung der Wahrscheinlichkeiten für Nachfolgetext und ergänzen diese um weitere Methoden. Im Prinzip funktionieren sie aber weiterhin so, dass sie Wahrscheinlichkeiten für Nachfolgetext schätzen. Die wiederholte Auswahl eines wahrscheinlichen Nachfolgers führt zur Erzeugung von Text, der je nach Kontext wirkt, als wäre er von Menschen geschrieben. Diese Vorhersage basiert auf statistischer Plausibilität, erzeugt allerdings auch manchmal faktisch falsche Aussagen, da der Text nicht auf inhaltliche Korrektheit geprüft wird. Diese Fehler sind mal mehr, mal weniger offensichtlich.
Anmerkungen:
- Dieser Blogeintrag geht nicht auf die technische Umsetzung von LLMs, wie word embedding, Transformer, Attention, Nachtraining mit menschlicher Rückmeldung), ein.
- Ebenfalls nicht berücksichtigt sind Verzerrungen, welche in solchen Systemen enthalten sind.
- Die Häufigkeiten der Wörter und Buchstaben entstammen:
- Die Häufigkeiten in diesem Text unterscheiden zur Vereinfachung nicht zwischen Groß- und Kleinbuchstaben.
Dieser Text wurde von Menschenhand geschrieben. Large Language Models (LLMs) wurden nur zur Erzeugung der Beispiele verwendet.